From Bottleneck to Breakthrough: How Wix Cut Kafka Costs by 30% with a Push-Based Consumer Proxy
- Wix Engineering
- Feb 26
- 11 min read
Updated: Mar 31

In this post, I will share the story of migrating Wix’s backend services to use Kafka via a push-based consumer proxy. I’ll address the motivations for adopting this pattern, including the technical aspects of building a consumer proxy, and the results of the migration.
Background
Wix’s backbone consists of over 4,000 of small micro-services and serverless functions performing isolated tasks, all communicating with each other via synchronous gRPC calls or asynchronously via Kafka.
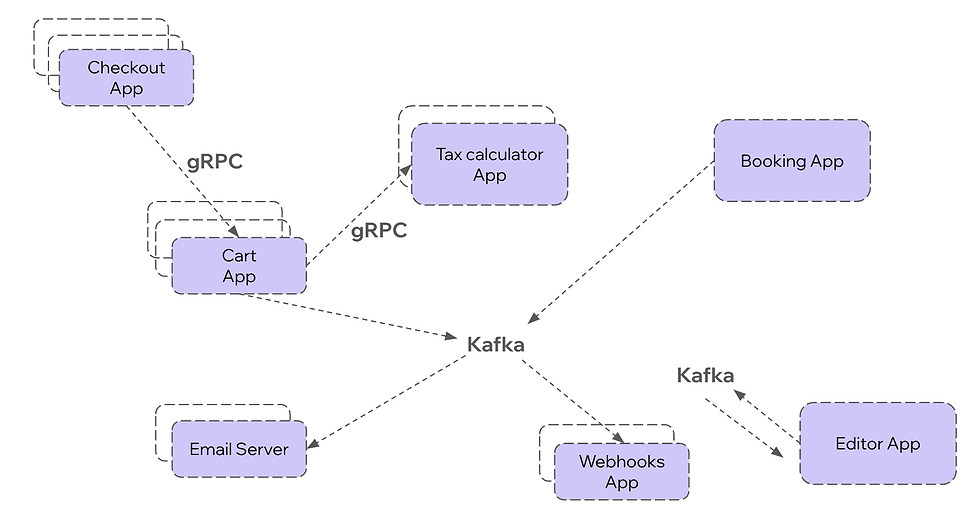
Whether a backend service is written in Scala, Typescript or Python (all used at Wix), Kafka message production and consumption are done using our client library Greyhound, which abstracts many common concerns for Wix services. Non-JVM services run Kafka consumers via a Kubernetes “sidecar app” that runs the Greyhound client. JVM services just use Greyhound as a library.
Greyhound was initially developed to support a limited number of clients during the early days of asynchronous messaging emergence at Wix. In addition to simplifying APIs for Wix apps, it was built to be fast, support as much throughput as possible, and with minimal latency.
Over the years, as async communication became a critical component of almost every backend service, maintaining the infrastructure to support the ever growing workload has become a financial challenge.
In 2020, we migrated our entire Kafka infrastructure to the cloud, choosing Confluent as the provider. While at first, this move alleviated the immediate maintenance pains, as workloads continued to increase each year, my team was tasked with finding ways to reduce our monthly bill.
Thanks to our standards of using Kafka solely via Greyhound, we are always able to perform cross-company changes when needed. All we needed to do is change something in Greyhound, and deploy apps with the new cheaper version!
Our unique situation
As we started the cost-saving initiative, we took a look at our Kafka bill to see what could be trimmed. We found that we spend: Around 10% on write throughput, 40% on reads throughput and 40-50% on provisioned capacity (CKU), which is equivalent to the number of brokers that are provisioned to support the workload.

To keep this post short, we’ll skip to the part where we figured out: If we’re paying for Reads 4x more than for Writes, and reading a byte costs the same as writing a byte, it means we’re consuming each produced byte 4 times (on average)!
This makes sense - we have many Kafka topics that are consumed by many different consumer groups.
If we could find a way to cache written data and consume it from Kafka just once, for all of the consumer groups, we will have saved 30% of the Kafka bill. Moreover, if we can reduce those excessive reads, surely our cluster load will drop, allowing us to scale down much of our clusters’ size.
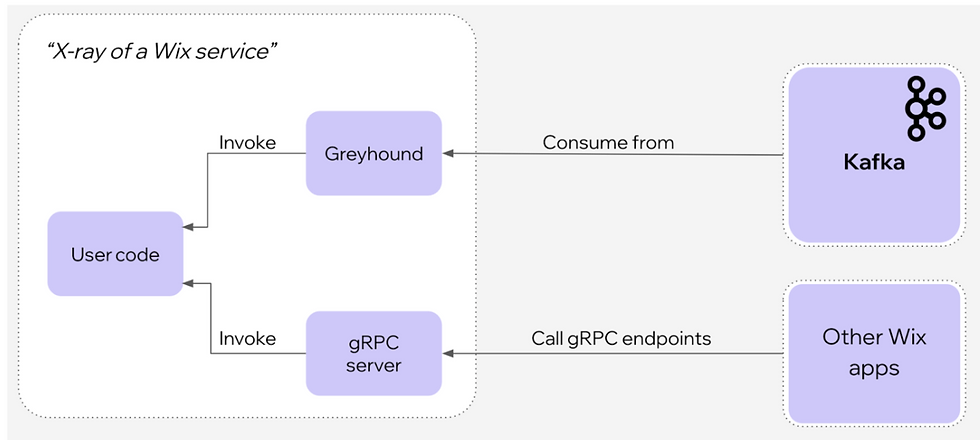
To do this - we decided to build a new mechanism for consuming Kafka topics. Instead of providing the library that reads messages directly from Kafka, we will consume all the topics from a dedicated service and push the data to the clients via gRPC. This should allow plenty of room for caching data locally in one location, if done correctly.
Since all clients already use Greyhound, it was pretty straightforward for us to change the underlying Greyhound code from using the Kafka consumer SDK, to simply exposing a gRPC endpoint to be called by our new proxy service. The tricky part was building the proxy itself.
Illustration of our environment before Consumer Proxy (consumers work directly with Kafka):
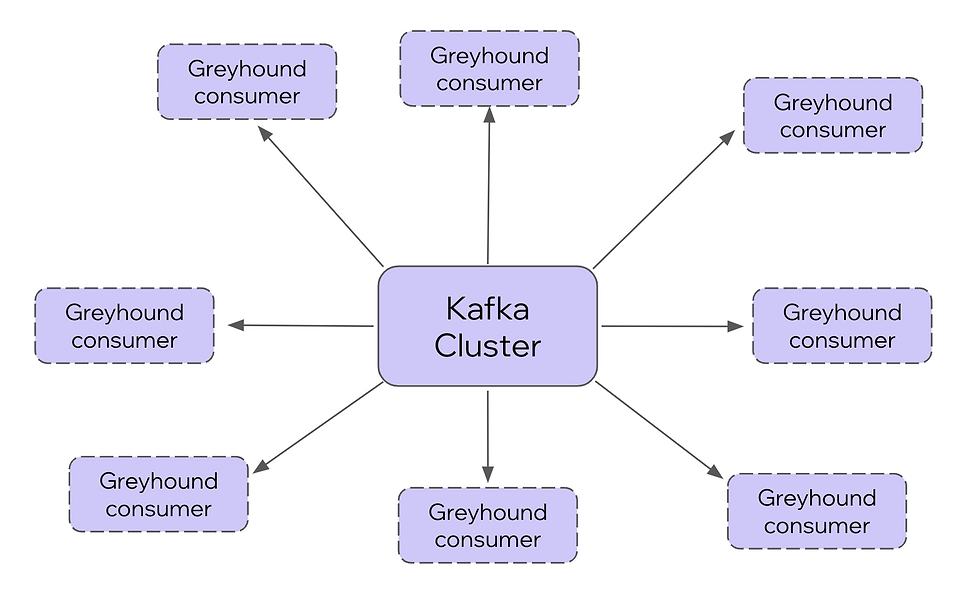
A single service:
And now (Consumer proxy connects to Kafka and pushes data to the clients):
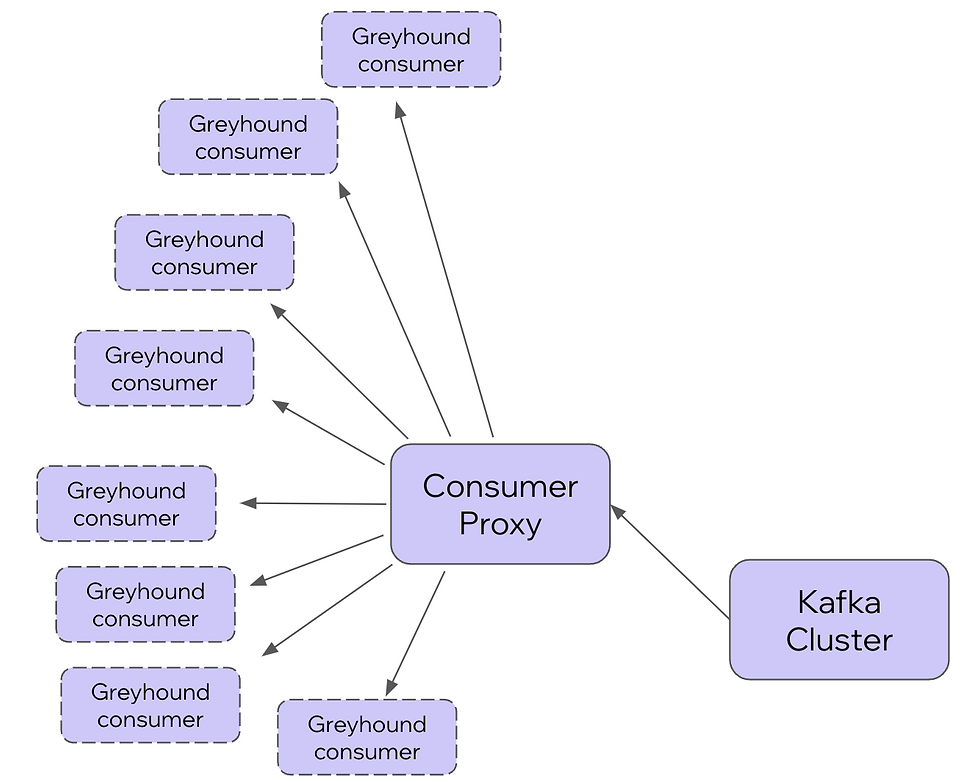
Single service:
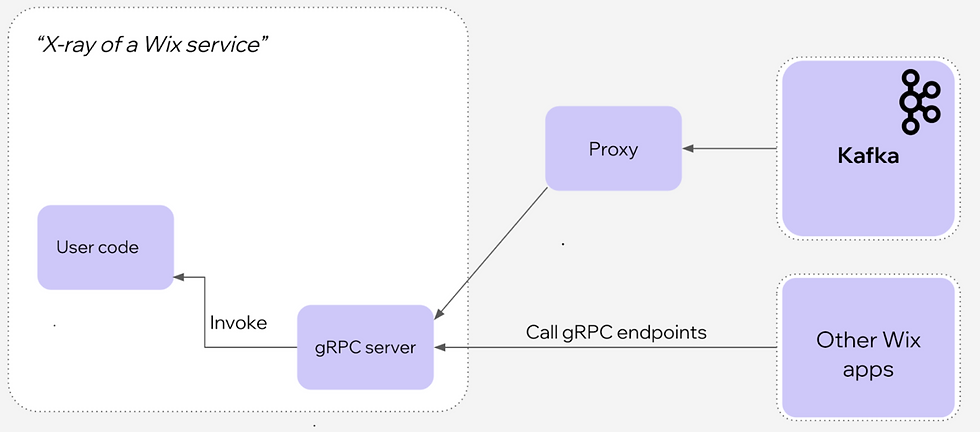
Building a Kafka consumer proxy
Building a proxy that can handle the entire workload of Wix’s Kafka backend traffic is tricky. It would replace code that is running on thousands of services, but would need to do it efficiently enough to not become a production burden. Greyhound is fast, but it costs CPU and memory. If we were naive enough to simply run thousands of “Greyhound” instances, the proxy would need thousands of pods just to handle the load.
The standard Kafka loop
So what is a Greyhound consumer instance? Same as most other Kafka consumer applications. Greyhound simply does the general boilerplate and provides a simpler callback API.
We can see the general idea in Confluent’s post. Something like this:
var consumer = new KafkaConsumer<>({“consumer.group.id”: “app-1”, …});
try {
consumer.subscribe(topics);
while (keepConsuming) {
var consumerRecords = consumer.poll();
process(consumerRecords);
consumer.commit(
committableOffsets(consumerRecords)
)
}
} finally consumer.close();Why this paradigm can’t work as a proxy
A consumer proxy has to relay topics on behalf of multiple consumer groups. In our case, thousands of consumer groups. But Kafka’s Consumer SDK is initialized with a single consumer group. In order to build a consumer proxy using this pattern, we would have to construct thousands of consumer instances, each with its own processing loop.
We actually tried that. Our first proxy POC implementation literally started a Greyhound instance per consumer group. It failed fast (too many resources to support the load), so we proceeded to design and build a new implementation from scratch.
Consumer proxy architecture
Goes without saying, any good proxy must be horizontally scalable, allowing quick auto-scaling with more/less proxy instances as required by throughput.
Here are the basic moving parts for the proxy (within a single proxy instance):
Work distribution (aka Leader election).
A Kafka consumer loop that writes all consumed topics to local storage.
A processing loop that reads from local storage and invokes clients with records via gRPC and commits offsets on behalf of the consumer groups.

In addition we will need to persist consumer registrations. Any database could work (we used DynamoDB).
Before going into the moving parts that comprise a consumer proxy instance, first we defined how clients interact with the proxy.
High level flow:
In order to consume topics from Kafka:
A client calls the proxy’s registration endpoint via gRPC, specifying a list of “ConsumerSpec”s in the request payload.
A ConsumerSpec specifies the consumer group that the client is consuming on behalf, and the list of topics it wants to consume (and some optional configurations).
The proxy stores the registrations in the database, which in turn triggers (when necessary) a rebalance of work between proxy instances.
Each consumer proxy instance serves a partial workload, fetches records from Kafka topics and pushes them to the clients via gRPC.
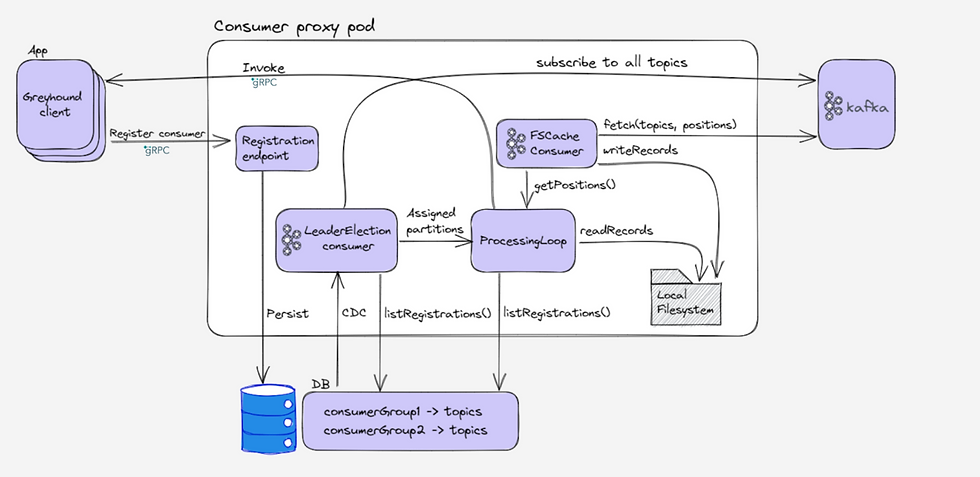
Consumer proxy’s 3 moving parts - in detail
Part 1: Work distribution (AKA Leader election)
Let’s define the problem:Given that our input is a list of registered “ConsumerSpec”s, and a list of currently running proxy instances, we should assign the processing so that workload is distributed as equally as possible between proxy instances”.
A naive approach: What if we (somehow) assign a list of “ConsumerSpec”s for each proxy instance, where each will process the consumer groups specified in their respective specs. The first problem with this approach: distribution might not be ideal, as some instances may be assigned to higher throughput topics, while others get idle topics.
A bigger problem is that some topics could be assigned to more than 1 instance! But wait, why is that a problem? Because caching won’t work well!
If we want to read each record only once, we need all of the consumers that subscribed to a specific topic to be assigned to the same instance.
So our problem statement might have been incomplete. Let’s add a requirement: “.. and each record is fetched from Kafka a minimal number of times”.
Perhaps our input (a list of consumer specs) is a bit too vague. Remember Kafka topics are actually a number of TopicPartitions. So we could use a more precise granularity when defining our input.
Let’s define this granular unit of work:
An Assignment is a (Topic,Partition,ConsumerGroupId) triplet.

Now let’s redefine the problem:
Given our input is a list of assignments, and a list of currently running proxy instances, we should distribute the processing so that workload is distributed as equally as possible between proxy instances (and each record is fetched from Kafka a minimal number of times).
To solve this problem, ideally we would try and assign an equal number of assignments to each pod (for good distribution), but also try to keep assignments of the same partitions assigned to the same proxy instances (to maximize caching).
Initially we tried to roll our own “leader election” mechanism to do just that. Not going into too much detail, our main take-away from that attempt was: Never roll your own leader election. Prefer using something that already works.
And which leader election process do we know that works? The Kafka consumer protocol itself! What does that mean exactly, and how can we utilize this to distribute the assignments?If all the proxy instances start a Kafka consumer with a shared consumer group id, and they all subscribe to all the registered topics, then each would be assigned an equal number of topic-partitions. So once a proxy instance is assigned its topic-partitions, it can figure out which consumer groups are registered to those topics, based on the registrations DB.
Does this solution answer all of our requirements? Kinda.
Can we cache records efficiently now? Yes, by design! Because all consumer groups associated with a topic-partition now have to be processed by a single instance, which happens to be assigned to that topic-partition, given we use a regular Kafka consumer rebalance protocol.
Are assignments distributed equally between instances? Almost. Because each topic is consumed by a different number of consumer groups, we cannot guarantee that work is equally distributed. However, since topic-partitions are relatively spread out to all instances, in practice the workload is actually distributed equally, given that most topics have enough partitions to be spread across all proxy instances.
So there we have it - our first part of building the consumer proxy is the leader election process, which is in fact a simple loop over the Kafka consumer, used solely for the sake of topic-partition assignment.
Wait, won’t subscribing to all the topics automatically fetch the data as well?Yes, it will - and we don’t want that since we cover that in “Part 3 (ingress)”.
To avoid fetching from Kafka we can simply call the “pause” method on the Kafka consumer, specifying all the topic-partitions. This way we can keep on polling from Kafka, but not fetching data.
Here’s what our leader election process would roughly look like:
var consumer = new KafkaConsumer<>({“consumer.group.id”: “consumer-proxy-leader-election-group”}); try {
val allTopics = db.getAllConsumerRegistrations().map(_.topics)
consumer.subscribe(allTopics, onPartitionsAssignedCallback, onPartitionsRemovedCallback);
while (true) {
consumer.pause(allPartitions(topics))
consumer.poll(); }
} finally consumer.close();
def onPartitionsAssignedCallback = (partitions: Seq[Int]) =>
processor.addAssignments(partitions)
def onPartitionsRemovedCallback = (partitions: Seq[Int]) =>
processor.removeAssignments(partitions)Ignore the processor (we’ll get to it in the next part) for now and focus on the mechanism:
We retrieve the list of topics to be consumed.
We subscribe to those topics, and provide a call-back which will trigger start/stop of assignments.
Start a loop that will never actually fetch data (because it is always paused). This triggers a consumer rebalance when necessary, but no records are fetched from Kafka.
Part 2 - Egress: The user-land processor
The processor maintains a state of all its assignments. It keeps runtime data for each assignment, most importantly:- in-progress RPC requests to clients- The position of the next message to consume in a partition, for each consumer group who consumes it. It is actually the next Kafka offset.
The processor starts an infinite loop: in each iteration it reads the current state, and if there’s no active gRPC request currently open - it will fetch records from local storage (on how records get to the disk - in the next part), starting from the position of the assignment. If we get records - a batch gRPC request is issued to the relevant client.
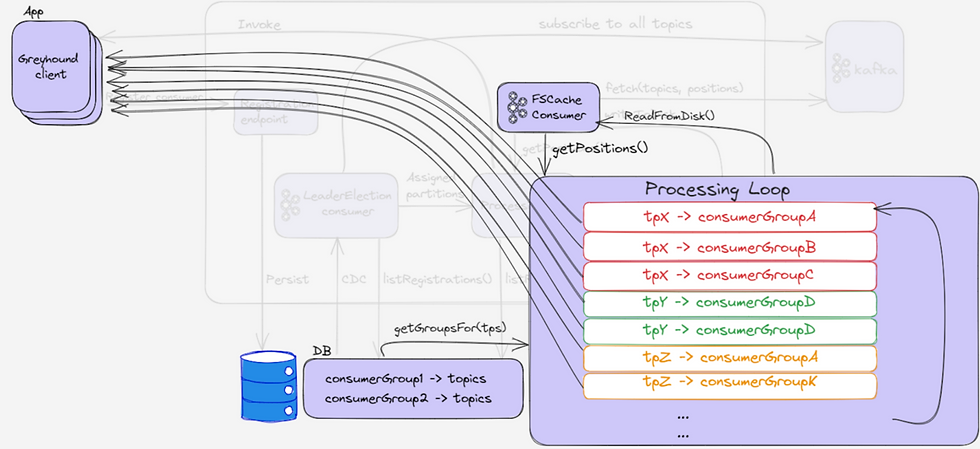
Avoiding contention
We don’t want a slow client to affect other clients, so the gRPC requests to clients are done in a separate execution context (fancy words for “other thread”). In fact, to keep things very fast, we also perform the reads from the disk on a separate thread, which helps keep the processing loop super fast.
Routing requests to the clients
How do we actually reach our clients?
That’s easy: Wix already has a robust mechanism to route gRPC between services. All we need is to store the service identifier when it is registering, and use that identifier when issuing the requests. But this is just our specific implementation. This architecture doesn’t actually require communication to be specifically over gRPC: all it requires is to store some kind of “return address” to the consumers when they register.
Reacting to rebalances/assignment changes
When the leader-election consumer rebalances (due to instances being replaced or changes to consumer registrations), it will invoke the user-land processor by requesting to add or remove assignments. When assignments are removed, we make sure to gracefully wait until clients complete processing current records before completing the callback.
There is a caveat here: since all consumer groups are sharing the leader election process, slower clients can cause long halts during rebalances. To keep things relatively fast, we set our global timeout to 15 seconds. So when clients don’t complete processing within that time, we will release the assignments and continue rebalancing.
This means clients that take longer than that to complete processing a batch of messages will have to deal with consumption of duplicate records.
Part 3: Ingress - The Kafka-land processor
For the user-land processor to work, we need to pre-fetch data on behalf of the clients, and always make sure they have records available for processing.
The tricky part is that some topics have multiple consumer groups consuming them, while each may be processing at different speeds. We need to make sure that each consumer group gets data as fast as they can process it, while sharing a single KafkaConsumer.
So our ingress processor will need to act as something of a “Scheduler”, which assigns consumer time slots to different consumer groups.
Here’s a rough implementation we started with (strictly pseudo-code):
def ingressLoop(leaderElection: LeaderElection, egressProcessor: EgressProcessor) = {
val consumer = new KafkaConsumer(..) // no consumer group!
while (true) {
consumer.assign(leaderElection.assignedPartitions)
val nextPositions =
getFairPositions(egressProcessor.currentAssignments)
consumer.seek(nextPositions)
val records = consumer.poll()
writeToDisk(records)
}
def getFairPositions(assignments: Seq[Assignment]):
Map[TopicPartition, Offset] = …Before fetching new records, we use the KafkaConsumer’s ‘seek’ method to fetch from the most relevant offsets. To Find that, the getFairPositions function is used to sort each group of consumer groups per topic-partition, based mostly on how many available cached records there are locally for each consumer group. The consumer group that has the least available records will usually be awarded the time slot.
Greyhound features
To successfully migrate all of Wix services to the new proxy we had to implement all of the features that Greyhound supports. To name a few:
Blocking and non blocking retries
Dead-letter-queues
Parallel consumption (Ordered by key and unordered)
Delayed consumption
Consumer proxy sharding
The number of Assignments the consumer proxy has to process is over 100,000 at the time of writing this post. In order to reduce the blast radius of potential catastrophic events, we decided to split the proxy into multiple shards. The sharding is based on the hash of the topic names, so no topic is processed by more than one shard. This is important if we want to avoid excessive consumption of topics.
This also means we get to roll out our proxy changes more gradually, one shard at a time.
Results
Wix maintains well over 4,000 services in production, 2500 of which use Kafka. At this time we have successfully migrated 90% of them - which means we get to bear the fruits of our labor!
Over the course of the last year, Write traffic to our clusters has increased by 2x, while our Read traffic has reduced by 2x! This means we have basically removed almost all of the redundant reads from our clusters. How did this happen? Exactly how we imagined it to: Topics that were consumed multiple times are only consumed once thanks to our caching mechanism. We’ve migrated the heaviest consumers that account for most of the traffic first, helping us achieve our goals of reducing total costs by 30%.
Data Streams team @ Wix
Shoutout to all the awesome team members for building this thing:
Omri Chen, Maya Bachar, Or Ben Ari, Shani Michael and Assaf Jaffi!


This post was written by Noam Berman
More of Wix Engineering's updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel
Comments