Moving Velo to Multiple Container Sites: The Why, The How and The Lessons Learned
- Wix Engineering
- May 30, 2021
- 5 min read
Updated: Jul 4, 2021
Intro
Velo by Wix (formally known as Corvid) is a framework that allows Wix users to write backend and frontend code for their sites. Although this new level of customization is a huge leap forward, in terms of functionality, Wix’s rapid growth surely introduced new challenges.
Velo was initially designed to be very cost effective, to support tens of millions of small customers. As we grew, one of the challenges was the introduction of larger clients that needed more resources. From the Velo perspective it means running the application backend code on more than one container.
In order to do so we had to rebuild our entire infrastructure - this is how “Kore” was born.

Photo by Andrey Sharpilo Hire on Unsplash
About Kore
Kore (Kubernetes Orchestrated Runtime Engine) is a computational grid that is responsible for the orchestration of backend code execution. Kore is replacing an older grid that used Docker containers without any 3rd party high level orchestration mechanisms that caused us to write a proprietary orchestration mechanism that was complex and hard to scale.
The natural direction was to choose Kubernetes as an umbrella for our grid capabilities. But it wasn’t enough, Wix has tight response time constraints which made naive solutions insufficient. Here are the two of them:
Whenever a user triggered the Velo backend, we could spawn a pod to run the needed code. However, in this solution we would get slow response time for our first request (aka cold start). Just spawning the pod takes, comparatively, a while.
Always keep a pod for each Wix site that uses Velo. Although it could fit some premium clients, because of the long tail nature of Wix (few sites have a lot of traffic and many sites have low traffic) it is wasteful to sustain such a state.
Finally, the solution we went for was to keep a pool of pods that are available for receiving traffic. A pod in a “pooled” state has all the internals to serve traffic but until triggered, it doesn’t do anything except for being warmed up.
When we need to serve a Velo site that has some backend code, we can pick one of the pooled pods and affiliate it to the site. From now on, the pod will serve only this particular site until it’s recycled, which happens after a few minutes. After the pod is recycled, given there is still traffic to the site, a new pooled pod will be picked to serve it and so on.
For example, let’s consider a site with the following backend code:

It is a GET rest endpoint that returns a static piece of data.
Once triggered, the following happens:

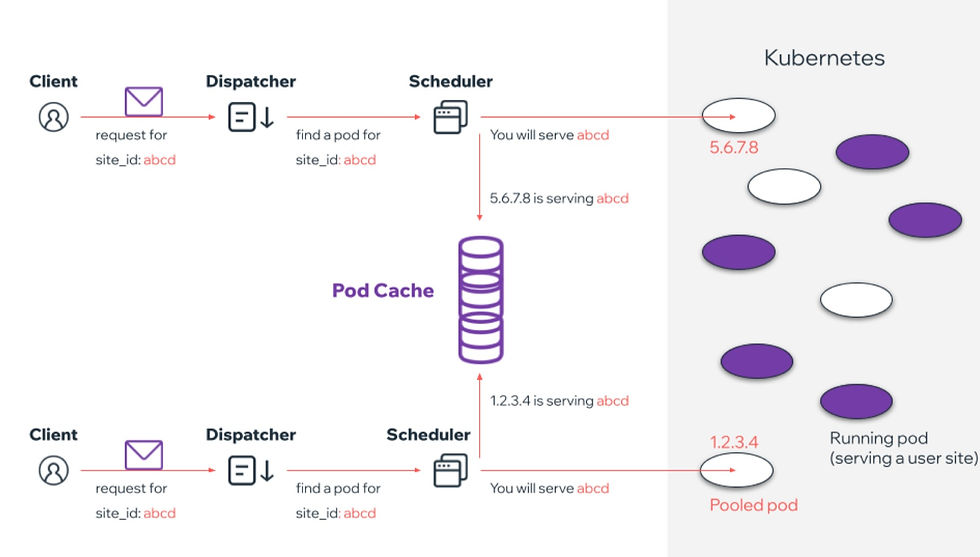
The Dispatcher service receives a request and has to find a pod on which the code will run. In order to do so, it calls the scheduler service for service discovery with the site_id of the user’s site.

Since at this point the application wasn’t yet triggered, the scheduler has to find a pooled pod in order to attach to it the site’s backend code. It is simply done by randomly choosing a Pod that is labeled as “pooled”. Once a pod is locked for our site, its details are stored in Pod Cache so next time a request arrives for our site, the scheduler won’t provision another pod but just return the address of the already provisioned pod.

The dispatcher now receives the address of the pod that is serving the site’s backend code as response to its request. After the pod is affiliated to a certain site it starts a startup sequence in which it installs the user code so its runtime can serve the incoming traffic.
“A free scaling mechanism”
Kore is a distributed and scalable solution, and is meant for operational resiliency in high load environments. Kore components are designed with high availability in mind and are built with failover mechanisms, including the scheduler.
Here we can see that a single site now runs on two different pods. Provisioning a pod to run user code is a long process. Therefore, when there is no provisioned pod in the pod cache (that we can direct the traffic to without provisioning) and if two simultaneous requests are dispatched, the Schedulers aren’t aware of each other and can’t know that the two of them are processing the same site. The result is two provisioned pods that are serving the same site.
This “scenario” is considered normal behavior of the system. In a case where more than one pod is registered in Pod Cache for a single site, for the following requests, the scheduler will choose one pod randomly.
Multi pod sites
The above solution works great for the casual sites that have some traffic but nothing that challenges the system performance-wise. But what if we want to host a site that has a significant amount of traffic? In that case, one pod (or accidentally two, see above) will struggle to provide the needed performance.
In order to address this use case we can configure pods per site, i.e, for each site, how many pods do we want it to spin up.
First step was to create a simple service that controls the amount of pods a single site can run. Its data looks something like this:

The second step was the actual pod provisioning process.
Here we wanted to achieve a few goals:
Increase the number of pods only when there’s traffic to the site.
Avoid creating too many pods.
Do not slow down the provision flow described above.

The “Async pod provisioning” is happening in the background and therefore we don’t slow down the main service discovery flow.
What’s happening in the “Async pod provisioning” is we want to find out two things:
How many pods are currently serving our site.
How many pods should actually serve our site.
Pod Cache stores how many pods are currently running and from the Props service we can know the expected maximum number of pods.
Once Kore collects all the data it needs, it decides whether additional pods need to be provisioned or not. If more pods are needed, Kore will provision exactly one more pod. This is done in order to gradually increase the amount of pods and to avoid overprovisioning by multiple schedulers that are running in the cluster.
As described above, we can overprovision by some small number of pods, which is reasonable practice for operational and service stability and availability purposes.
Conclusions
The scaling implementation described in this article fits our needs for two main reasons. On one hand It solves a problem: now we can have sites that are utilizing multiple containers, which brings in great value. On the other hand, it was a natural evolution of our current system and therefore, pretty fast and straightforward to develop.
Running Velo sites on multiple containers is a complex domain, therefore, creating a solution that would bring us maximum value without bending the existing and working architecture was a safe way to start.
Sometimes good engineering is “hitting walls” as soon as possible and there is no better way to do so except for delivering a solution to production with real users and use cases. This way we can find our shortcomings fast and adjust accordingly.

This post was written by Michael Irzh
You can follow him on Twitter
For more engineering updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel
ความคิดเห็น