Before we begin: I’d like to first point out that it doesn’t really matter what the source and the destination databases are in the context of this article as the principles are quite general. There are many reasons for migrating a database; this article won’t cover them. In this blog post we’ll approach the issue at hand from the standpoint of a use case we had at Wix Inbox.
Wix is a world class website builder that lets you create any website you want. We’ve got over 200 million users in 190 countries.
Wix Inbox is part of the Wix CRM solution - a one stop shop for site owners to manage all of their communication with site visitors and contacts. It’s also the one place where all of the site visitors’ events and actions can be viewed.

Photo by the blowup on Unsplash
The Challenge
Our chat application in Wix used self-managed Cassandra clusters that ran on AWS EC2 instances and served multiple microservices. As we grew, our Cassandra cluster became more and more unstable, and became the cause of several service outages. There were a couple of reasons for this.
First, uneven partitions and hotspots affected performance and created uneven pressure on certain Cassandra nodes which even resulted in node crashes and downtime. This was caused by having the chatroom id as partition key. It so happens that chat rooms are not equal in neither traffic nor size.
Second, as part of the natural evolution of our product there came a need for new ways to access the data (access pattern), not necessarily using the entire primary key. In order to meet the new patterns in an efficient manner a secondary index had to be added to our Cassandra table. Later we even found ourselves adding a materialized view to support new requirements.
These two factors, along with our growth in scale, added stress to the cluster.
Lastly, we realized only a few people at Wix knew Cassandra intimately enough, which makes it difficult to maintain.
A journey towards a solution
I’ll start with one of the main takeaways from our journey:
A deep understanding of the data will light the way for choosing both the right technology and the right approach for data migration.
A piece of advice: you might want to adopt a certain technology, or have a good working knowledge of some database and may be sure it fits your use case. Well, even if it’s hard, start by putting technology aside. As if all options are on the table. We’ll get back to choosing the right technology and migration process once we understand our data better.
Our journey pointed us to some guidelines in understanding our data that we found useful in the decision-making process:
Most important! How do you access your data? Know your access patterns:
Reads
Writes
Single / Multi region
SLA
Is your data mutable or immutable?
That is to say: do your records change after they are written?
Is the data time bounded?
Is your data relevant for a certain period of time, which means it can be discarded afterwards?
Is data transformation or schema change needed during migration, or are we planning to migrate the data as is?
What’s the size of data? Is full migration even feasible?
These are some of the central questions that helped us decide on a migration strategy. They pointed us to 3 main possible approaches to migrating the data. Luckily (or not), we had the privilege to use all 3 approaches.
Migrating time bounded data
We have a microservice in Wix Inbox that holds data for online / offline site visitors. It allows our users to see whether they have live visitors on their website in real time and potentially initiate a conversation with them.
Let’s examine our data in this use case:
While our data is not immutable, immutability might be a stronger requirement than what we actually need here. Changes to our data are always full overwrites where all of the fields of the item are supplied in every write action.
For obvious reasons, this data has a short life span (We used Cassandra TTLs, so there can be no data that is older than our defined time window). As we serve traffic from multiple geographical locations, our solution should be multi region (replicated). No data transformation is needed here and we keep the same schema.
We also wrote down all of our access patterns, reads and writes.
We chose AWS DynamoDB, and the migration approach we implemented was the following:
Lifecycle-based Data Migration Approach:

We opened production writes to both data sources:
We wrote to Cassandra, and immediately following that, to DynamoDB. If either of the writes failed, the entire request would fail. As each write is new or fully overwrites existing data, a user could retry the request and the state would remain consistent.
This approach saves us (most of) the headache of handling possible inconsistencies between the two databases.
After one full data lifecycle (meaning waiting until all live data has gone through the new logic) - both data sources should contain the same data.
At this point we switched production reads and writes to the new data source.
Last but not least, we dropped the old datasource.
An important note here - at each stage (up until 3), we still kept writing to Cassandra, which is the old database, which meant that we were able to rollback at any moment and move back to the old solution.
Approaching the elephant in the room
The second Cassandra cluster we had contained all of the messages ever sent in our application. We’re talking about several Terabytes of data.
Again, we started by examining our data:
As in the previous case, this type of data must also be replicated between regions. We wrote down all of our access patterns (for example, get x last messages from a chatroom, count messages since x, get messages with a certain filter, add messages). Unlike the previous case, here the data is permanent and should be fully migrated. Luckily and importantly our messages are immutable. They do not change after they are created. This greatly simplified things for us. Unfortunately, we had to transform the data, and the schema changed a bit accordingly.
We eventually chose AWS DynamoDB for this type of data as well, as it supported our requirements including our access patterns and scale.
We decided to go with what some might argue is the classic data migration approach:
Arbitrary Data - Iterative Migration Approach:

Since the application and the source Cassandra cluster were working and serving production traffic, our main concern was to have as minimal effect (if any at all) on production as possible. The overall process can be roughly described in this manner:
Start writing to DynamoDB as well as Cassandra in production (*).
Take a snapshot of the Cassandra cluster and create a clone - to be the source for the migration, so it won’t affect production.
Migrate all data from the clone to the new database
Move production reads to the new database.
* Important tip here, we first opened the DynamoDB writes inside a try-catch block which only reported errors and did not fail write requests (‘shadow mode’). This allowed us to first let traffic rise and let DynamoDB ‘warm up’ before putting it in the critical chain.
After writes traffic to DynamoDB was stable, while closely monitoring it, we removed the try-catch clause, making writing to DynamoDB necessary for a request to succeed.
That enabled us to get to know the new database better at our scale, before having it impact production.
Specifically in the case of migrating to DynamoDB there are a couple of tools available in AWS that can help with that, which are worth taking a look at. They are relevant to this exact migration approach. There’s the AWS Schema Conversion Tool and the AWS Database Migration Service. In our use case it was easier to migrate using the application, so we did not use these tools.
We started a POC for this migration, for a smaller table we had (a couple of GBs in total), and discovered 2 important findings:
During the migration, we iterated over all Cassandra data (pages). Having metrics on everything, we still felt completely blind on the migration process - how far it progressed, how much time was left, etc.
After this POC was completed, we discovered that our clone cluster had missing data and that not all data was transferred.
These 2 things were unacceptable for our messages data migration, which contained a lot more data to transfer.
It was time to go back to the drawing board. Rather than spending time and resources (which we didn’t have) on creating a reliable clone, we decided to change the migration strategy with 2 main goals in mind:
Have certainty that all data will be migrated.
Have great visibility into the migration status at every moment.
The first goal meant we needed the production serving cluster be the source of the migration.
The second one... required some thinking.
We took a closer look at our access patterns. We saw that each time we access the messages’ data, it’s for a specific chatroom. This told us that if we would be able to somehow distinguish between newly created chatrooms and older ones, and perhaps route production reads of those new ones to the new database, we’d be able to migrate older messages by chatrooms, and that way make sure that all chatroom messages are migrated for sure. In other words, we would be able to treat our data as incremental (aggregate it under one entity, and know the datasource to use for each entity).
Using this approach, depending on the size of the data, it’s sometimes even possible to leave the older data in the old database and avoid migration altogether. This could be a safer bet if your goal is not to completely stop using the old database.
‘Incremental’ Data Migration Approach:
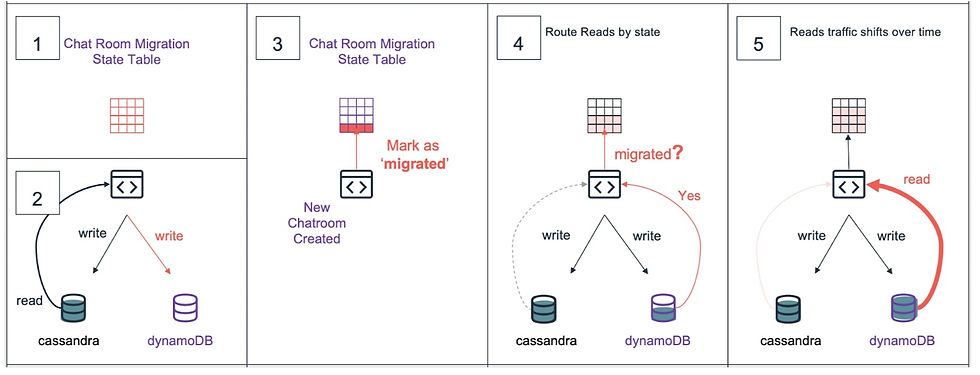
So, a new approach was born:
A DynamoDB ‘Chatroom Migration State’ table was created. Each item held a specific chatroom migration status. Whether it is ongoing, ended, or maybe never even started (if record is absent).
We write new data to both data sources (as described above).
We mark newly created chatrooms as migrated in the status table - since they are created empty and all new messages will be written to the new database too.
Each production read:
Checks if migration of a chatroom has already ended.
If it did, read its messages from DynamoDB.
Otherwise it read them from Cassandra.
* This obviously added some time to each request, but it really wasn’t significant.
After some time, Cassandra read traffic decreased significantly. The longer we waited, the less traffic went to the Cassandra cluster. At that point it became much simpler and safer to begin migration of the historic data, as the Cassandra cluster was no longer under high load.
Having the information of each chatroom creation date, we triggered migration, month by month, steadily going back in time.
As migration ran, production reads became less and less dependent on Cassandra, until it became completely obsolete.
The main benefit here, apart from having the visibility into the process and certainty of the migrated data, is that the move was gradual. There was no one peak point where we moved production reads from one source to another.
Second, we kept the ability to ‘rollback’ to the previous setup up until the very last moment. That gave us confidence to proceed.
Some additional notes:
Writing to both databases obviously requires more resources from the application (heap, cpu, GC), keep that in mind.
We took into consideration that the phase of writing to both databases will increase write request latency a bit, but it was acceptable for us and definitely worth the rollback ability it provided.
In conclusion - Important lessons learned
Know your data. Its properties will lead the way to a right database solution, and the right migration approach.
Let the new datasource handle real traffic early. If something goes wrong, or there’s some anomaly, there's a better chance to quickly reveal it.
Make sure you have a simple method to rollback. Writes to Cassandra (the old data source) continued in parallel with writes to the new datasource. This gave us the ability at any time to just go back to Cassandra if something went wrong.
Monitoring is key. Have metrics on everything. Without them you’re practically blind. It helps in building confidence that things are going as expected and to make the right decisions in the process.
This pretty much sums up our journey. As there are many technologies and database solutions, there are different ways to handle the data migration. In any case, always start with knowing your data.
If you want to learn more about safe database migration you can read about it here.

This post was written by David Vaks
For more engineering updates and insights:
Join our Telegram channel
Visit us on GitHub
Subscribe to our YouTube channel
Comments